
Een robots.txt-bestand is een tekstbestand in de rootmap van je website dat richtlijnen geeft aan zoekmachinebots. Het vertelt deze bots welke delen van je website ze wel en niet mogen crawlen. Dit is cruciaal voor het optimaliseren van je website, omdat het:
- Voorkomt dat niet-relevante content wordt geïndexeerd (zoals je admin-map of plugindirectory).
- Helpt om dubbele content te vermijden, waardoor zoekmachines niet onnodig tijd besteden aan vergelijkbare pagina’s.
Hoe werkt een Robots.txt-bestand?
Wanneer zoekmachines een nieuwe website ontdekken, sturen ze crawlers om informatie te verzamelen. Deze crawlers indexeren je pagina’s en gebruiken een robots.txt-bestand als gids om te bepalen welke delen van de site ze moeten bezoeken.
Uitleg
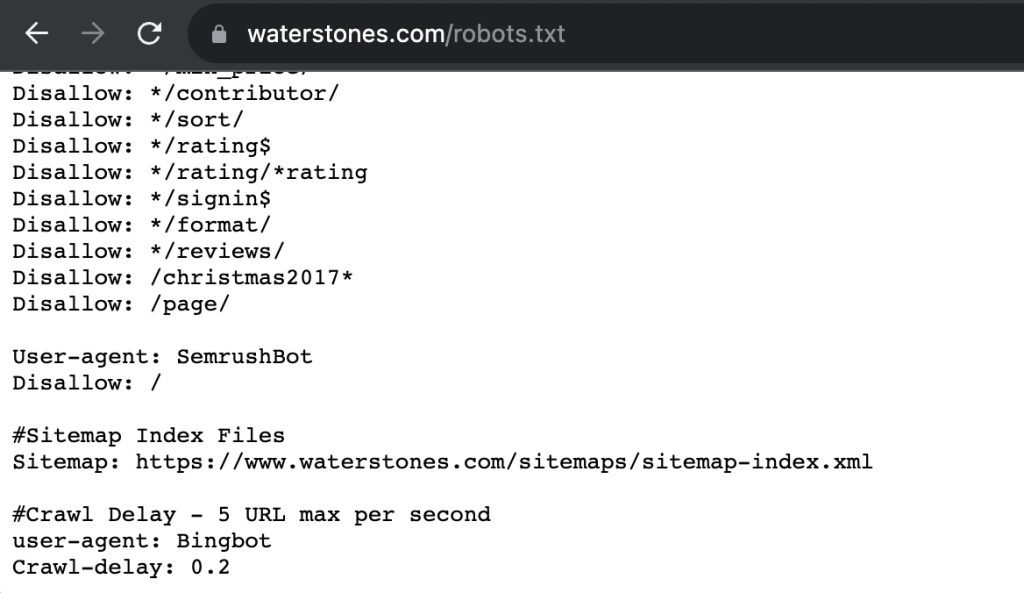
Laten we het bestand verder verduidelijken met specifieke voorbeelden van /christmas2017, /page/, en het dollarteken ($).
Disallow: /christmas2017*- Uitleg: Het sterretje (
*) betekent dat alle URL’s die beginnen met/christmas2017worden geblokkeerd voor zoekmachinebots. - Voorbeeld:
/christmas2017-sale/christmas2017/gifts
Dit helpt om oude of tijdelijke pagina’s, zoals seizoensgebonden acties, uit de zoekresultaten te houden.
- Uitleg: Het sterretje (
Disallow: /page/- Uitleg: Deze regel blokkeert alle URL’s die beginnen met
/page/. Dit kan bijvoorbeeld voorkomen dat paginanummers of archiefpagina’s in de zoekresultaten verschijnen. - Voorbeeld:
/page/2/page/3
Dit is nuttig om duplicaten of niet-relevante pagina’s te vermijden.
- Uitleg: Deze regel blokkeert alle URL’s die beginnen met
- Gebruik van het dollarteken (
$)- Regel:
Disallow: */rating$- Uitleg: Het dollarteken (
$) betekent dat alleen URL’s die precies eindigen op/ratingworden geblokkeerd.
- Uitleg: Het dollarteken (
- Voorbeeld:
- Wel geblokkeerd:
/product/rating - Niet geblokkeerd:
/product/rating/details
- Wel geblokkeerd:
- Regel:
Waarom het gebruiken van robots.txt belangrijk is?
Een robots.txt-bestand is cruciaal om zoekmachines effectief te sturen bij het crawlen van je website. Zoekmachines hebben een beperkt crawlbudget, wat betekent dat ze maar een bepaalde hoeveelheid pagina’s kunnen bezoeken binnen een bepaalde tijd. Zonder richtlijnen kunnen bots onbelangrijke of irrelevante pagina’s crawlen, zoals oude campagnes (/christmas2017*) of paginering (/page/). Hierdoor wordt kostbare tijd verspild, terwijl belangrijke pagina’s mogelijk over het hoofd worden gezien.
Door onnodige pagina’s uit te sluiten, richt je de aandacht van zoekmachines op content die daadwerkelijk bijdraagt aan je SEO-prestaties. Dit zorgt ervoor dat je belangrijkste pagina’s, zoals productpagina’s, blogs of landingspagina’s, sneller worden geïndexeerd en beter kunnen ranken in zoekmachines.
Conclusie
Een goed ingericht robots.txt-bestand is essentieel voor het optimaliseren van je website en het effectief benutten van het crawlbudget. Door zoekmachinebots duidelijke richtlijnen te geven over welke pagina’s ze wel of niet mogen crawlen, voorkom je dat onbelangrijke of dubbele content wordt geïndexeerd. Dit zorgt ervoor dat bots zich richten op waardevolle pagina’s die bijdragen aan je SEO-prestaties, zoals productpagina’s, blogs en landingspagina’s.
Vond je deze blog interessant? Houd dan onze kennisbank in de gaten.