
Elke dag gebruiken miljoenen mensen zoekmachines om snel en effectief informatie te vinden. Maar hoe werkt dat eigenlijk? Hoe weten zoekmachines wat er op jouw website staat, en hoe zorg je ervoor dat jouw pagina bovenaan verschijnt? Hier leggen we het proces uit, stap voor stap.
Hoe werkt een zoekmachine?
Stel je het internet voor als een enorme bibliotheek met miljoenen boeken. Zoekmachines fungeren als superslimme bibliothecarissen, die razendsnel het juiste boek of de juiste informatie weten te vinden. Dit proces verloopt in een aantal stappen:
1. Crawlen
Zoekmachines sturen robots, ook wel spiders genoemd, op pad om alle webpagina’s te doorzoeken. Deze robots bekijken welke pagina’s er zijn, waar ze over gaan en hoe ze met andere pagina’s verbonden zijn via links. Ze houden daarbij rekening met instructies in het robots.txt-bestand, waarin je kunt aangeven welke pagina’s de robots wel of niet mogen lezen.
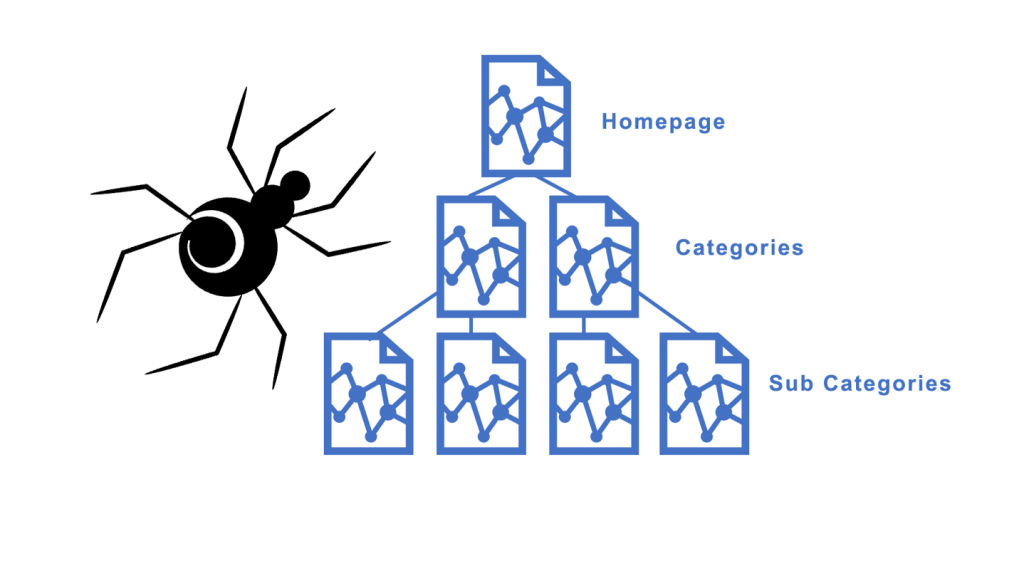
2. Renderen
Sommige websites bevatten complexe elementen zoals interactieve afbeeldingen. Door het proces van renderen kunnen zoekmachines deze elementen beter begrijpen. Het is alsof ze een speciale bril opzetten, waardoor ze de site bekijken zoals een bezoeker dat zou doen.
3. Indexeren
Nadat de robots een pagina hebben bekeken, wordt de informatie georganiseerd en opgeslagen in een gigantische index. Dit is te vergelijken met een kaartenbak in een bibliotheek, waar je snel kunt opzoeken welk boek over een specifiek onderwerp gaat. Bij belangrijke pagina’s wordt soms een kopie opgeslagen, een zogenaamde gecachte versie, zodat de pagina snel geladen kan worden.
Het toevoegen van een sitemap kan dit proces versnellen, omdat het zoekmachines een duidelijke routekaart geeft naar alle belangrijke pagina’s op je site. Vooral voor grote of complexe websites helpt een sitemap om pagina’s efficiënter te laten crawlen en indexeren.
4. Ranking en zoekresultaten tonen
Wanneer je een zoekopdracht invoert, doorzoekt de zoekmachine de index om de meest relevante resultaten te vinden. Hierbij spelen signalen zoals de kwaliteit van de content, het gebruik van zoekwoorden en de betrouwbaarheid van de website een rol. Vervolgens rangschikt de zoekmachine de resultaten en toont deze aan jou.
Wat is een crawlbudget?
Zoekmachines hebben een beperkt aantal pagina’s dat ze per dag kunnen bezoeken op jouw site. Dit wordt het crawlbudget genoemd. Als je veel pagina’s hebt, is het belangrijk om de belangrijkste pagina’s goed vindbaar te maken. Zo kunnen robots hun tijd efficiënt besteden.
Benieuwd hoe zoekmachines jouw website crawlen en hoe je inzicht krijgt in jouw crawlbudget? Wist je dat je met Google Search Console precies kunt zien hoe vaak Google jouw website bezoekt en welke pagina’s het meest worden gecrawld? Dit en meer ontdek je in ons artikel: “Inzicht in crawlbudget via Google search console?“
Waar wordt het crawlbudget door beïnvloed?
Het crawlbudget wordt beïnvloed door twee belangrijke factoren:
- Crawl rate: Dit is het maximale aantal verzoeken dat een zoekmachinebot tegelijk naar jouw site kan sturen, zonder je server te overbelasten. Als je server snel en betrouwbaar is, verhoogt Google de crawl rate.
- Crawl demand: Dit is hoe vaak Google een bepaalde pagina wil crawlen. Dit hangt af van de populariteit van de pagina en hoe vaak de content verandert.
Vond je dit interessant? Houd dan onze kennisbank in de gaten voor meer artikelen.